




Mostanában a csapból is az folyik, hogy mesterséges intelligencia meg tanuló algoritmusok, arról azonban nem nagyon esik szó, hogy mégis mi ez az egész, mire jó és milyen elven működik. Nem véletlenül: elképesztően bonyolult témáról van szó. Ennek ellenére a cikkem célja az, hogy akár teljesen laikusként legyen némi rálátásod a területre.
A médiában a „mesterséges intelligencia” és a „tanuló algoritmus” kifejezések majdnem mindig a mesterséges neurális hálózatokat takarják. A cikkben ezekről lesz szó.
Azért kapták ezt a jól csengő nevet, mert a biológiai neurális hálózatok, főleg az emberi idegrendszer ihlette őket. A hagyományos szoftverekkel szemben ezek anélkül képesek megoldani egy problémát, hogy a megoldás konkrét lépéseit megmondanánk nekik. Nem előre lekódolt utasításokat hajtanak végre, hanem „rájönnek", hogyan kell megoldani a problémákat.
Tanulnak. Ez alatt azt értjük, hogy a korábbi tapasztalataikat felhasználva egyre jobban és jobban tudják végrehajtani az adott feladatot egészen addig, amíg végül képesek lesznek magabiztosan egy elfogadható hibahatáron belül teljesíteni.
Hogyan tanulnak az emberek?
Először azt kell megértened, hogy te hogyan tanulsz. Nagyon leegyszerűsítve ezt a következőképpen tudom összefoglalni:
Az agyadban található neuronok az idegrendszered legfontosabb feldolgozó egységei. Van bemenetük (dentrit) és kimenetük (axon), amelyeken keresztül más neuronokkal állnak kapcsolatban. Egymáshoz össze-vissza csatlakozva bonyolult hálózatot alkotnak.
Amikor kisbaba voltál, az agyad még csak negyedakkora volt, mint most, de már csaknem az összes neuront tartalmazta, amelyeket azóta is használsz. A tanulás során a neuronok között kapcsolatok (szinapszisok) jönnek létre vagy szűnnek meg. Ezért érdemes folyamatosan képezned magad.
Valójában persze sokkal bonyolultabb a dolog, de a lényeg így is látszik: a tanulás előtti és utáni állapotok között a legfontosabb különbség nem magukban az idegsejtekben, hanem a köztük kialakult kapcsolatokban rejlik. Felfoghatod úgy is, hogy minden, amit valaha megtanultál, leírható ezekkel a kapcsolatokkal.
Hogyan tanulnak a gépek?
Kis túlzással ugyanígy. Gépi tanuló algoritmusok fejlesztésekor is neuronokból építkezünk, amelyeket egymással összekötünk, majd a tanulás során ezeket a „szinapszisokat” úgynevezett közelítő megoldások alapján folyamatosan módosítjuk. Az a cél, hogy úgy drótozzuk át a neuronok hálózatát, hogy az minél pontosabban legyen képes végrehajtani az adott feladatot.
Úgy gondolom, egy konkrét példán keresztül egyszerűbben megérthető ez az egész. Nézzük meg, hogyan képes egy algoritmus megtanulni a XOR függvényt!
A XOR (kizáró vagy) két paramétert kap, amelyek lehetnek igazak (1) vagy hamisak (0). Ha a két paraméter különbözik, akkor 1 lesz az eredmény, egyezés esetén pedig nulla. Tehát:
XOR(0,0) = 0
XOR(0,1) = 1
XOR(1,0) = 1
XOR(1,1) = 0
A hálózat felépítése
A hálózatunk tehát neuronokból és kapcsolatokból áll. A neuron gyakorlatilag egy függvény: van bemenete, van kimenete, a kettő között pedig csinál valamit a kapott adatokkal.
A mi neuronjaink a logisztikai szigmoid függvényt fogják használni.
Maga a hálózat három rétegből épül fel:
- egy bemeneti réteg, amelyben két neuron kap helyet a két bemeneti értéknek
- egy rejtett réteg három neuronnal
- egy kimeneti réteg egyetlen kimeneti neuronnal
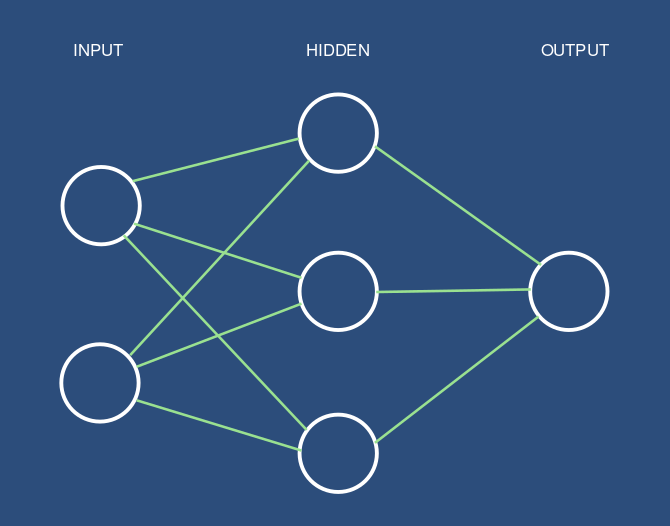
Ahogyan a fenti ábrán is látható, minden réteg összes neuronját összekötjük a következő réteg összes neuronjával (ezt nevezzük előrecsatolásnak). Az így létrejött kapcsolatoknak súlyokat adunk, amelyeket először random számokkal inicializálunk.
Maga a network ezzel már majdnem készen van, csak egyelőre nem nagyon működik. Még nem tudja, hogy mit várunk tőle. Meg kell neki tanítanunk, vagyis a kapcsolatok súlyait úgy kell beállítanunk, hogy a várt működést elérjük.
A hálózat tanítása
Mivel meg tudjuk mondani, hogy egy adott bemenetre milyen kimenetet kell kapnunk, úgynevezett felügyelt tanítási módszert fogunk alkalmazni. Szükség lesz egy tanítási adathalmazra (training set). Esetünkben ez a XOR függvény négy lehetséges bemenetét és a hozzájuk tartozó kimeneteket jelenti.
A tanítás kezdetén egyből a mély vízbe dobjuk a hálózatot. Adunk neki egy mintát, aztán megnézzük, hogy mekkorát tévedett a várt kimenethez képest. A tévedés függvényében állítunk egy kicsit a súlyokon, majd ezt ismételjük egészen addig, amíg úgy nem döntünk, hogy a hálózatunk már elég okos. Esetünkben akkor döntünk így, amikor a meghatározottnál kisebb hibával sikerült eltalálnia a várt kimenetet. Nézzük meg egy kicsit közelebbről!
Az eredmény kiszámítása
Tehát a hálózat súlyait korábban már random számokkal inicializáltuk (az egyszerűség kedvéért legalábbis közelítsük meg így). Tegyük fel, hogy mindegyik kapcsolat súlya 0.5 lett.
Veszünk egy mintát (például 0 és 1 a bemenet, a várt kimenet pedig 1). Ezt a mintát betoljuk a hálózatunkba az input rétegen keresztül, amely két neuront tartalmaz. Ezek kimenete így 0 és 1 lesz.
A középső, rejtett rétegünk neuronjai csatlakoznak a bemeneti réteg két neuronjához. Fogjuk az első neuron első kapcsolatát, majd a kapcsolat súlyát megszorozzuk a kapcsolódó bemeneti neuron kiemnetével (0 * 0.5 = 0). A második kapcsolatnál ugyanígy járunk el (1 * 0.5 = 0.5), majd a két számot összeadjuk (0 + 0.5 = 0.5). Az eredményt átengedjük a neuron „sejtmagján”, a logisztikai függvényen (1 / (1 + exp(-0.5)) = 0.62). Így járunk el a további két rejtett neuron esetében is.
Az utolsó, kimeneti rétegben hasonlóképpen számolunk, ezzel megkapjuk a hálózatunk tényleges eredményét. Nem vezetem le, mert annyira nem érdekes, de először a hálózat kimenete valahol 0.5 környékén lesz.
A súlyok igazítása
A hálózatunk által produkált kimenetet összevetjük azzal az eredménnyel, amit kapnunk kellett volna, majd a hibát visszavezetjük a hálózatba (ezért nevezzük backpropagation-nek). Úgy is mondhatnám, hogy levonjuk a konklúziót és ennek függvényében változtatunk egy kicsit a súlyokon.
Ezúttal visszafelé haladunk a rétegeken. Először is minden egyes neuron esetében meg kell határoznunk a hiba mértékét. Ehhez az átlagos négyzetes hibafüggvényt hívjuk segítségül. Minél ügyesebb volt a hálózatunk, annál kisebb lesz a hibafüggvénnyel kiszámolt eredmény, tehát annál kisebb változtatásra lesz szükség.
Már csak a „szinapszisok” finomhangolása van hátra. De honnan tudjuk, hogy az adott kapcsolat módosítása hogyan fog kihatni a hálózatunk működésére? Pontosabban: melyiket hogyan kell módosítanunk a pontosabb eredmény érdekében? A választ az általánosított delta szabály alkalmazásával kapjuk meg. Röviden összefoglalva arról van szó, hogy minden egyes kapcsolat súlyát a hiba létrehozásában játszott szerepükkel arányosan változtatjuk.
A következő körben így egy kicsivel pontosabb lesz a számítás, így előbb-utóbb a hálózat a várt működést fogja mutatni.
Vizualizáció
Arra gondoltam, hogy mindezt könnyebben megértheted, ha a saját szemeddel látod, hogyan lesz súlyok módosítgatásából tanulás. Ez adta az ötletet egy olyan microsite fejlesztéséhez, amely mindezt lehetővé teszi. Itt nézheted meg.
Amit látsz: a fenti példában vázolt egyszerű hálózat felépül és megtanulja a XOR függvényt néhány másodperc alatt. Minden tizedik epoch (1 epoch = a teljes tanítási adatkészletet végigpörgettük a hálózaton, esetünkben ez 4 iteráció) után készül egy „pillanatkép” a hálózat aktuális állapotáról.
A folyamatot vissza tudod játszani az alsó csúszka mozgatásával, így láthatod, hogyan alakultak át a hálózat kapcsolatai és milyen eredmények születtek. Mivel az elején véletlenszerűen inicializált súlyokkal jön létre a hálózat, az eredmény mindig egy kicsit más lesz.
A site forráskódja is elérhető.
Megjegyzés: a vizualizáció során úgynevezett biased neuronokat használtam, amelyek a hálózat optimálisabb (esetünkben gyorsabb) működését teszik lehetővé. Enélkül is működne, így az egyszerűség kedvéért ezek az értékek nem jelennek meg.
Írd meg a saját hálózatod!
Szóval arra bíztatlak, ha érdekel ez a világ, vágj bele és próbálj meg összedobni valamit még akkor is, ha elsőre túlságosan bonyolultnak tűnik az egész. Minden szépen ki fog tisztulni, ahogy az lenni szokott. :)
Figyelmedbe ajánlom a Synaptic JavaScript frameworköt, amelyet a microsite esetében is használtam. A framework egyrészt azért érdekes, mert használható kliensoldalon és szerveroldalon egyaránt, ezáltal lehetővé teszi a neurális hálózatok alkalmazását a weben.
Még ennél is érdekesebb lehet számodra az a tény, hogy pár osztályból áll az egész. Persze nem lehet egy lapon említeni olyan robosztus keretrendszerekkel, mint amilyen a TensorFlow vagy a Caffe2 (utóbbi egyébként a számomra a legszimpatikusabb), de pont az egyszerűsége teszi igazán alkalmassá arra, hogy elkezdj kicsit komolyabban foglalkozni a témával.
Az egyszerű XOR hálózat például ennyi:
// Hálózat két bemeneti, három rejtett és egy kimeneti neuronnal.
var myNetwork = new Architect.Perceptron(2,3,1);
// Trainer
var myTrainer = new Trainer(myNetwork);
// Tanítás a XOR training settel, átlagos négyzetes hibafüggvénnyel
myTrainer.XOR()
// Eredmény a [0, 1] bemenetre:
console.log( myNetwork.activate( [0, 1] ) );
Szóval hajrá!
Felhasználási területek
A XOR példa a neurális hálózatok hello world-je, ennek még nincs sok gyakorlati haszna. Kicsit bonyolultabb, de hasonló felépítésű hálózatok viszont már használhatóak például osztályozási feladatokra. Használhatsz másmilyen neuronokat, sokkal többet, több rejtett rétegben. Nem csak előrecsatolással kötheted össze őket, hanem például visszacsatolással. Taníthatod valamilyen nem felügyelt eljárással, így elvontabb problémákat is megoldhatsz, ahol nem annyira egyértelmű, mi számít elfogadható eredménynek.
Egy visszacsatolt neurális hálózatnak (RNN) lehet memóriája (LSTM), ami képessé teszi adatok iterációk közötti átvitelére, így alkalmas lesz távolabbi összefüggéseket is feltárni. Ezt használjuk például természetes nyelvfeldolgozásnál. Ekkor már neurális nyelvi modellekről beszélünk, amelyek szavak vagy betűk szintjén keresnek összefüggéseket a szövegekben. Azt tudják megmondani, hogy egy mondat mekkora valószínűséggel fordulhat elő a való életben. Jobbá teszik például a fordítóprogramokat, mert életszerűbb fordításokat eredményeznek.
Szinte ugyanezzel a technológiával költhetsz vereseket vagy megírhatod a Trónok Harca befejezését. Skip-Trough vektorokkal még életszerűbb mondatokat generálhatsz, amelyekről már nem feltétlenül mondanád meg, hogy egy számítógép írta őket. Felismerhetsz képeken látható tárgyakat, sőt, történeteket generálhatsz képek alapján.
A weben is számos területen bevethetőek. Ajánlhatsz termékeket egy webshopban. Színpalettát generálhatsz. Chatbotokat készíthetsz. Nagyobb biztonságban tudhatod az adataidat. Értékes információkat bányászhatsz ki a felhasználóid viselkedéséből. Olyan összefüggéseket, amelyekről most még nem is tudod, hogy figyelned kellene rájuk.
Sokáig azt hittük, hogy bizonyos dolgokra csak mi, emberek vagyunk képesek. Régebben például egyszerű captcha megoldásokkal távol lehetett tartani a robotokat. Ma már nem.
Szeretnéd legyőzni a világ legjobb Dota2 játékosát, de nem vagy profi gamer? Nem probléma, mesterséges intelligenciával ezt is bármikor megteheted. Fáradt vagy és nincs kedved autót vezetni? Dőlj hátra, egy neurális hálózat simán elvezeti a kocsidat helyetted, ráadásul sokkal jobban.
Ez nem a jövő, ez a jelen. Hogy hol a határ? Sehol. Nincs határ. A lehetőségek tárháza végtelen és a technológia napjainkban rohamléptekben fejlődik. Csak egy dolog biztos: előbb-utóbb okosabbak lesznek nálunk a számítógépeink, ez pedig alapjaiban fogja megváltozni a ma ismert világunkat. A tekintetben, hogy ez mennyire lesz jó nekünk, megoszlanak a vélemények. Ha engem kérdezel, jogosnak tartom az aggályokat, de azért bizakodó vagyok.
És Te mit gondolsz?
