



A címben MySQL szerepel, de a poszt inkább a MariaDB nevezetű forkról fog szólni, és annak különböző nagy rendelkezésre állású megoldásairól, külön kitérve, hol melyik megoldás működik, vagy épp inkompatibilis egymással.
MariaDB vs. MySQL
Pár szóban a MariaDB-ről azoknak, akik nem ismernék. A történet egészen addig nyúlik vissza, mikor az Oracle felvásárolta a MySQL AB-t a Sun-on keresztül. Az eredeti fejlesztőcsapat megalakította a MariaDB Foundation-t, és forkolta a MySQL-t. Amíg a MySQL fejlesztése és funkcióbővítése megmaradt az Oracle fejlesztők kezében, azt az Oracle üzleti igényei befolyásolják, addig a MariaDB fejlesztését a közösség viszi előre, szem előtt tartva, hogy amennyire lehet a MariaDB binárisan kompatibilis maradjon a MySQL-lel, ellenben sok közösségi igényű újdonsággal kibővítse az eredeti működést.
High Availability
A rövid kitérő után visszatérve a bejegyzés eredeti témájához. A nagy rendelkezésre állással (HA - High Availability) kapcsolatban még tisztázni kell egy alapvető elméletet, a CAP tételt.
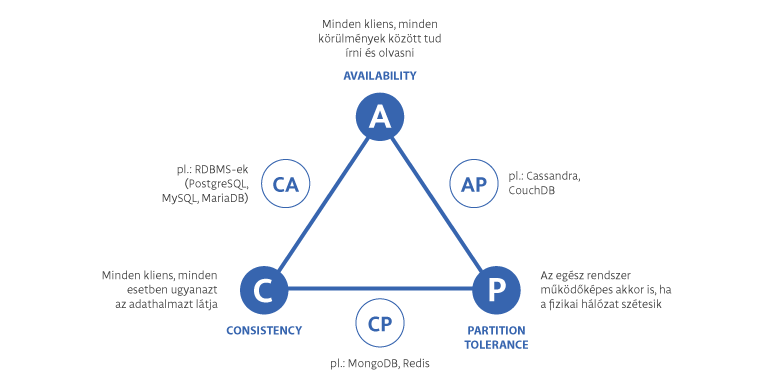
A rövidítés a Consistency (Konzisztencia), Availability (Rendelkezésre állás) és a Partition tolerability (Partíció-tűrés) kezdőbetűiből áll össze. Konzisztencia esetén minden egyes lekérdezésnél ugyanazokat az adatokat kell visszaadnia az egész rendszernek, rendelkezésre állás esetén a rendszer minden részének elérhetőnek kell lennie, partíció-tűrés esetén pedig az egész rendszer működőképes marad akkor is, ha a rendszer valamilyen okból kifolyólag szétesik kisebb, önállóan működőképes egységekre. Ebből a 3 tulajdonságból egy rendszerben csak 2 lehet jelen egyszerre.
A relációs adatbáziskezelő rendszerek a CA vonalon mozognak, azaz az adatok konzisztensek és elérhetőek, ez felel meg az ACID (Atomicity – atomicitás, Consistency – konzisztencia, Isolation – izoláció, és Durability – tartósság) elveknek is. A Partíció-tűréssel az a probléma RDBMS-ek (Relációs adatbáziskezelő rendszerek) esetén, hogy ha szétesik a rendszer, adminisztrátor legyen a talpán, aki újra összeszinkronizálja a szétesett partíciókat, ezt hívják Split-Brain helyzetnek. Ugye senki nem akar ilyet!
Nagy rendelkezésre állású rendszereknél így kulcsfontosságú működés a fencing, azaz valahogy a renitens rendszert elkülöníteni a többitől. Ebből következik, hogy legalább 3 elemű rendszernek kell lennie, így többségi szavazás alapján el lehet dönteni, melyik elemet kell kizárni. Ennek a legbrutálisabb, egyben leghatékonyabb esete az, a STONITH (Shoot The Offending Node In The Head), azaz egyszerűen lekapcsolják a szinkronból kiesett rendszert. Ez a gyakorlatban úgy működik, hogy a HA kezelő szoftver megkerülve mindent, direktben a szerver menedzsment kapcsolatán keresztül végrehajt egy force shutdown-t. Kész, lehalt, lelőtték, és jó esetben minden megy tovább, csak esetleg kicsit lassabban.
A folytatás ezt követően elég egyszerű, a leállított szerver ténye kivált egy riasztást az adminok felé, hogy leállt, ők elindítják a problémás szervert izoláltan és valamilyen módon átmásolják a szinkronban lévő rendszerből a helyes adatokat. Innentől kezdve a kiesett node visszailleszthető az egész rendszerbe.
Mielőtt fejjel mennél a falnak és az első Google találat után felhúznád az első rendszered, érdemes mérlegelni, mire is van szükséged, és a rendszert használó alkalmazások mit támogatnak. Ebből a megközelítésből számos lehetőséged van, különböző céllal.
Master-slave replication
A klasszikus felállás, van egy fő szerver, ami dolgozik, és van egy meleg tartalék szerver, ahol minden megvan ugyanúgy, csak nem lehet rá írni. Ezt mindenki ismeri. Még a MySQL is.
2 fő felhasználási lehetősége van:
- folyamatos, közel valós idejű mentés biztosítása
- egyszerű terhelés elosztás olvasás intenzív feladatok esetén, mivel a slave node használható read-only módban
Master-master replication
A klasszikus master-slave replikáció megcsavarva egy kicsit. Ez is működik MySQL alatt. Ebben az esetben mindkét szerver írható és olvasható is egyben. A csavar ott van, hogy 1 darab master-master replikációs rendszer 2 darab master-slave replikációs rendszerből áll össze. Hogyan áll össze ez 2 szerver esetén? – teheted fel a kérdést. Hát egy ügyes trükk alkalmazásával, mindkét node egymás masterjei és slavejei is egy időben.
És pont itt rejlik az egész buktatója, ami miatt veszélyes. Mivel 2 szerverről van szó, egyszerű többséggel nem lehet eldönteni, kinél vannak friss adatok, kinél nem, így kulcsfontosságú a monitorozás, hogy él-e a szinkronizációs folyamat, illetve ha él is, mennyire van szinkronban, nem laggol, késik-e véletlenül? Hiszen, ha nem vagy arra felkészülve, hogy úgy nyers erőből beletégy sok-sok adatot az adatbázisba, amit már a hálózaton csak lassan bírsz átküldeni, akkor bizony inkonzisztencia lesz. Igazából ez a probléma bármilyen aszinkron replikációnál fennáll.
Felhasználási lehetőség:
- klasszikus terhelés elosztás, mondjuk round-robinnal
- High Availability, mondjuk Virtual IP-vel és keepalived-vel.
Multi-source replication
Ez a lehetőség a MySQL 5.7-es és a MariaDB 10.0-ás verziójától érhető el. Nagyban hozzájárult a lefejlesztéséhez, hogy a MySQL-nél és a MariaDB-nél is rájöttek, hogy azért vannak problémák ezekkel a nagy bináris logokkal, amiken keresztül az adatbázis szerverek kommunikáltak egymással. Ehelyett kitalálták a GTID (Global transaction Identifier) használatát. A technológia lényege, hogy a bináris logok egyrészt soronként tartalmazzák az adatokat, másrészt az összetartozó tranzakciókat egyedi számsorral jelölték meg, így replikáció esetén eldönthető nagyon egyszerűen, hogy egy adott tranzakció replikálva kerül, vagy sem. Egyszerűen meg kell nézni, hol áll a GTID.
Ennél a pontnál van nagy eltérés a MySQL és MariaDB GTID implementációjában, és innentől kezdve ez a két rendszer inkomptabilis egymással.
MySQL esetén a GTID egy karakterlánc és egy szám azonosító elválasztva egy :-al. Az első fele egy forrás megjelölő azonosító, mely a forrás szervert azonosítja, általában a server_uuid értéke. A másik fele egy tranzakciós azonosító, ami egy szekvencia szám, ami a tranzakciók végrehajtásának sorrendjét adja meg.
MariaDB esetén talán picit jobban és átláthatóbban csinálták meg az implementációt. Ebben az esetben a GTID 3 db számból áll, - jellel elválasztva. Az első szám egy domain azonosító, ami esetén nagyjából azt képes lefedni, hogy a binlog nem feltétlenül egy sima rendben lévő folyam, hanem akár több folyam is lehet egyszerre. A második szám egy szerver azonosító szám. A harmadik pedig meglepő módon egy tranzakció azonosító.
MariaDB [sql3]> show all slaves status\G;
*************************** 1. row ***************************
Connection_name: sql1
Slave_SQL_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_IO_State: Waiting for master to send event
Master_Host: sql1
Master_User: root
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: binlog.000004
Read_Master_Log_Pos: 1179
Relay_Log_File: sql3-relay-bin-sql1.000002
Relay_Log_Pos: 1464
Relay_Master_Log_File: binlog.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Skip_Counter: 0
Exec_Master_Log_Pos: 1179
Relay_Log_Space: 1766
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_Server_Id: 101
Using_Gtid: Current_Pos
Gtid_IO_Pos: 1-101-21,0-103-6,2-102-12
Parallel_Mode: conservative
Retried_transactions: 0
Max_relay_log_size: 1073741824
Executed_log_entries: 23
Slave_received_heartbeats: 350
Slave_heartbeat_period: 1800.000
Gtid_Slave_Pos: 0-103-8,1-101-21,2-102-18
*************************** 2. row ***************************
Connection_name: sql2
Slave_SQL_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_IO_State: Waiting for master to send event
Master_Host: sql2
Master_User: root
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: binlog.000004
Read_Master_Log_Pos: 1392
Relay_Log_File: sql3-relay-bin-sql2.000002
Relay_Log_Pos: 1677
Relay_Master_Log_File: binlog.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Skip_Counter: 0
Exec_Master_Log_Pos: 1392
Relay_Log_Space: 1979
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_Server_Id: 102
Using_Gtid: Current_Pos
Gtid_IO_Pos: 1-101-16,0-103-6,2-102-18
Parallel_Mode: conservative
Retried_transactions: 0
Max_relay_log_size: 1073741824
Executed_log_entries: 23
Slave_received_heartbeats: 349
Slave_heartbeat_period: 1800.000
Gtid_Slave_Pos: 0-103-8,1-101-21,2-102-18
2 rows in set (0.00 sec)Maga a multi-source replication alapja az, hogy egy slave node-nak, több master node adja az adatokat. A felhasználási területei inkább már nagyobb rendszerek kapcsán merül fel, például:
- egy folyamatos mentést tárolni az összes adatbázis szerverről, így nem kell mentés céljából bejárni az egész adatbázis farmot
- big data jellegű adatelemzés esetén, ahol esetlegesen az adatbázisok vagy adatbázis táblák particionálva vannak több szerver között, viszont statisztika kinyerése vagy mentés céljából egy helyen meg kell lennie minden adatnak időszakos olvasási elérés miatt
Galera cluster
A Galera cluster a MariaDB 10.1 része telepítéstől kezdve érhető el és semmilyen egyéb speciális telepítést nem igényel. A korábbi verziókhoz külön patchelt verzióként telepíthető, ugyanúgy, ahogy a MySQL-hez is.
A rendszer hátránya, hogy kizárólag InnoDB/XtraDB engine-nel használható, bár ha összeveted az InnoDB és MyISAM előny-hátrányait, valószínűleg úgy is InnoDB-t fogsz használni. Néhány megkötése van, mint pl. minden esetben kell primary key, különben nem tudja a DELETE metódusokat lefuttatni, és primary key nélküli táblák sorrendje különböző node-okon különböző sorrendben jelenhet meg, de végül is RDMS-ről van szó, nem NoSQL-ről. Másrészt érdemes a potenciálisan ütközést okozó, vagy nagy méretű kéréseket optimalizálni. Érdemes szem előtt tartani, hogy egy sort csak egyszer lehet egy időben módosítani, különben conflict lesz.
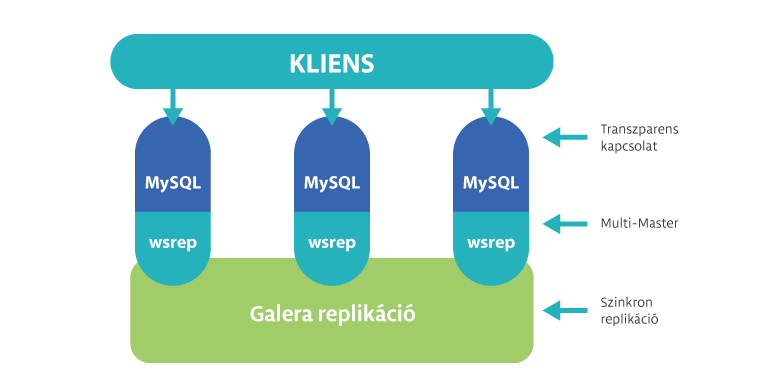
Számos előnye van a normál felállásos master-slave alapú replikációval szemben. A Galera cluster minden esetben multi-master replikációként lép fel, de egy saját wsrep API-t használ erre, nem a gyárilag beépített mysql replikációt. Mivel a normál MySQL protokoll helyett saját megoldáson kommunikál, így képes több mint 2 szerver esetén többségi szavazással (quorum) a particionált rendszert fenntartani, illetve új node belépése esetén automatikusan felszinkronizálni azt a teljes clusterhez. A saját API használatának másik hozadéka, hogy szinkron replikációt valósít, és erre képes nagy távolságú hálózatokon is, igaz írási folyamatok esetén a gyorsaság az ára ennek. Ezt a teljesítmény csökkenést szokták kompenzálni vegyes megoldásokkal, például adatközponton belül Galera cluster, adatközpontok között tradicionális multi-master replikáció, így kisebb gondot okoz a hálózati késleltetés.
ProxySQL
A ProxySQL nem klasszikusan egy adatbázis szerver, bár a konfigurációját egy MySQL alapú saját adatbázisban tárolja, hanem egy kiegészítő – meglepő módon – proxy szerver bármilyen cluster megoldáshoz.
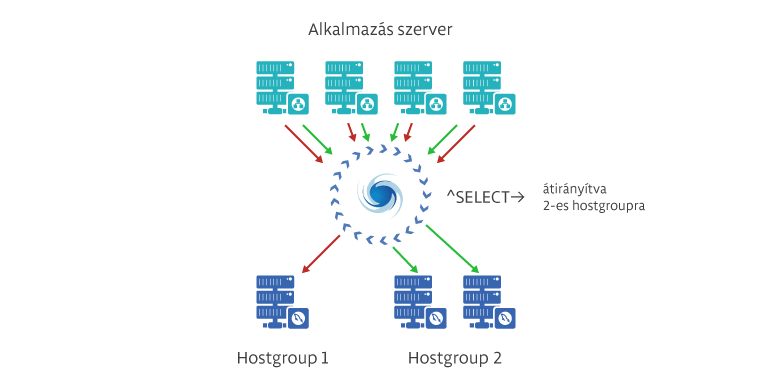
A ProxySQL erőssége abban rejlik, hogy széleskörűen testre szabható, így a felhasználási területének gyakorlatilag a kreativitás szab határt. Nyilván tud tartani szervereket, szerver csoportokat, amikhez kapcsolódik, avagy nem, azok között súlyozni, kapcsolódó felhasználói név alapján forgalmat irányítani. Van lehetőség SQL kérésekre, reguláris kifejezések alapján eldönteni, mely node-hoz menjen a forgalom, így szét lehet választani az írási és olvasási szervert. Virtuális IP-vel lehetőség van nagy rendelkezésre állású rendszert is építeni egy egyszerű keepalived-vel. Ahogy korábban írtam, a beállításait saját magában, MySQL alapú adatbázisban tárolja, így azt el lehet érni valós időben távolról is, így dinamikussá lehet tenni a működését. Reguláris kifejezésekkel meg lehet tiltani, hogy bizonyos kérések lefussanak, így akár egy tűzfal szerű működést is ki lehet hozni a rendszerből. Mindezt teszi úgy, hogy kihasználja a jelenlegi modern CPU-k több magos képességét, így nagy rendszerek is építhetőek vele.
Kooperáció
Jól látszik, hogy számos, egyszerűbb és komplexebb megoldás áll az üzemeltetők rendelkezésre, viszont jól látható cél, felhasználói és üzleti igény nélkül nehéz dönteni. Majdnem minden esetben nem árt, ha az üzemeltetői oldalról valaki leül a vezető fejlesztővel és esetleg az adatbázis tervezővel beszélgetni a készülő űrállomás méretű projektről, mivel az üzemeltetők és a fejlesztők életét is meg lehet könnyíteni, ha közösen dolgoznak. Biztosan fel kell készülniük a fejlesztőknek is arra, hogy az általuk fejlesztett kód képes legyen működni egy megtervezett HA környezetben. De ez már egy másik történet…
